Updated: Jun 04, 2025
Published: Dec 04, 2018
The Evolution of AI
Categories:
- Artificial Intelligence (AI) ,
- Robotics

Over the past few years, it seems like Artificial Intelligence (AI) is quietly becoming an integral part of our lives. Consider how common AI-infused products and services such as smart speakers (Amazon Echo, Google Home), self-driving cars (Tesla), smile recognition (smartphone camera app), and turn-by-turn directions have become. It’s hard to turn a corner without bumping into something that doesn’t use AI to make our lives easier.
More recently, there have also been a wide range of dystopian predictions for the future of AI – from AI taking our jobs, to triggering War World 3 to even reaching Singularity. So, is AI going to ruin our lives and take over the world or improve mankind? To understand where AI is today, its future, and where it’s headed, one has to understand its history. In this article, we’ll cover the evolution of AI starting with its birth through two AI winters to the current AI renaissance. Then we’ll look at the future of AI and how it might affect entertainment. To start, we’ll try and define Artificial Intelligence.
In this article:
What Is AI?
Everyone has a general sense of what AI entails, but let’s start with a basic definition from Merriam Webster:
- A branch of computer science dealing with the simulation of intelligent behavior in computers.
- The capability of a machine to imitate intelligent human behavior.
Common to both definitions is the idea of “human behavior” or “intelligent human behavior.” A better, and more concise definition, comes from Dr. Elaine Rich, who is a noted Computer Scientist and author of several books on Artificial Intelligence dating back to the 1980’s. In her 2009 edition of Artificial Intelligence, she states:
AI is the study of how to make computers do things which, at the moment, people do better.
Since the definition is based on the current capabilities of computers, this means that AI will change subtlety from year to year and dramatically from decade to decade. Whereas speech recognition, natural language understanding, and fingerprint recognition has become common place. Consider that this functionality was more fiction than reality a few decades earlier. In the 1966-67 Star Trek Original Series, remember Captain Kirk or Science Officer Spock wowing us by talking and consulting with the Enterprise’s computer? That capability isn’t too far from what we can do today with our smart speakers.
By definition, once a computer can do what people used to do better, it’s no longer AI. Would you call turn-by-turn directions based on current traffic conditions from Google Maps AI? Would you call smile detection, the ability for a camera to automatically take a photo when it detects everyone is smiling, AI? Someone from the 1970’s wearing bell bottoms grooving to the funky sounds of The Commodores probably would, but we wouldn’t today. In a way, AI is like magic.
AI Before Computers

Pascal’s mechanical calculator (1642) from Musee Des Arts Et Metiers in Paris, France – Source: John Hsia
The idea of thinking machines has its roots well before the first computers. While many in our day and age of smartphones and smart toothbrushes might find it hard to consider anything from centuries ago as smart, we only need to consider Elaine Rich’s definition of AI to realize how magical or intelligent some of these devices might have appeared at the time. Here are a few examples of clever machinery that appeared intelligent.
- 1023 BC Yan Shi from China: a life-sized walking and performing human automaton
- 350 BC Archyta from Italy: steam-driven flying pigeon
- 300 BC Ma Jun from China: hydraulic-powered puppet theatre with music
- 1200 Al-Jazari from Mesopotamia: musical robot band and mechanized wine servant
- 1495 Da Vinci from Italy: Robotic Knight capable of sitting, standing up and lifting its visor
- 1642 Blaise Pascal from France: a mechanical 6 digit calculator that adds and subtracts
- 1773 John Joseph Merlin from England: mechanized silver swan that preens itself and catches a fish
- 1770 Wolfgang von Kempelen from Hungary: the chess playing mechanical turk
Mechanical Turk and the Man Behind the Curtain
 The Chess Playing Mechanical Turk – Public Domain
The Chess Playing Mechanical Turk – Public DomainBefore anyone complains about my inclusion of the mechanical turk, I’ll caveat my reference to include that this contraption wasn’t an automaton or a robot of any kind. Instead it was a mechanized facade that was operated by a human who was cleverly hidden within the box. It toured Europe and the Americas masquerading as an automaton and played notable historic figures such as Napoleon, Benjamin Franklin and Edgar Allan Poe. Poe even wrote about his encounter. But this isn’t the end of the story.
In 2006, Amazon Web Services took this architecture to heart and created a crowdsourced marketplace for human workers called Amazon Mechanical Turk. If you wanted some “intelligent” work done (e.g. transcribe some audio), you would programmatically specify the Human Intelligent Tasks (HITs) and the criteria for acceptance of the HITs – this is the mechanical façade. Ultimately the work was done by a real human – the hidden person inside the box. At launch it was even self-described as artificial artificial intelligence (two artificials make one real).
Back to AI before computers …
In Pamela McCorduck’s 1979 book Machines Who Think (updated in 2004), she explores the idea and origins of AI and provides a succinct summary when she said “artificial intelligence in one form or another is an idea that has pervaded Western intellectual history, a dream in urgent need of being realized, expressed in humanity’s myths, legends, stories, speculation and clockwork automatons.” As you can see from some of the examples provided, the dream of AI existed across the planet and across millennium.
Does AI Owe Its Existence to Mathematics and Formal Reasoning?
Many modern technologies owe their existence to foundational work conducted centuries or a millennium ago. For example, some techniques for building skyscrapers originated from architectural experimentation with Romanesque and Gothic churches in medieval Europe. AI is no different.
Since AI essentially tries to mechanize human reasoning or logic, it’s dependent upon the ability to express or formalize logic. The study of logic goes back to 600BC with Logicians in China, Nyaya school of logic in India and Syllogism from Aristotle in Greece. In 800AD, Persian mathematician Muhhammad Al-Khwarizmi formalized algebra from which algorithms derives its name. Centuries later, philosophers and logicians like Ramon LLull (1232-1315) or Gottfried Leibniz (1645-1716) speculated about intelligent machines that could reason logically. This was followed by notable works by George Boole on Symbolic Logic and Boolean Algebra (1847) – both proved foundational to digital computers and AI.
My Early Encounter with AI
While not quite a millennium ago, I first encountered AI in the mid 80’s. Armed with a bachelor’s degree in Information and Computer Science (University of California, Irvine), I went to work for Texas Instruments as a Technical Sales Support Engineer on their Lisp Machine, the TI Explorer. Shortly afterwards, I was lured away to Symbolics, the market leader in Lisp Machines, and spent several years there in the heart of Aerospace corridor in Southern California.
We’ll discuss Lisp later, but for now, let’s just say that the computer language Lisp and Lisp Machines were the primary tools used by early AI researchers. Between working for Symbolics and interacting with Lisp Machine customers in the aerospace corridor in Southern California, I was fortunate to see some exciting applications related to the Space Shuttle, the Space Station, Intelligent CAD, Autonomous Vehicles and various DOD projects. AI was being widely researched for the enterprise and for defense, so my role in technical sales afforded me a unique opportunity to see a wide variety of AI applications across multiple industries and dozens of companies.
During this time, I had my first encounter with Artificial Neural Networks (ANN) at the University of Southern California. While Neural Networks was just one class in the Graduate program there, training my first ANN was eye opening to the possibilities.
After Symbolics, I went on to Inference Corporation, a leader in Expert Systems – an area within AI seeing success and adoption. At the time, Inference and Intellicorp were the top two leading Expert System shell companies. At Inference, I even had the privilege of supporting American Express’ deployment of AI for purchase authorizations. Over the course of five years and three companies, I witnessed both boom and bust with seemingly endless growth possibilities initially followed by closures and substantial layoffs. Seeing the recent AI hysteria, both good and bad, has caused me to reflect on the evolution of AI – past and present.
The history of AI is long and intertwined with the history of computers. To make this article more comprehensible, I’ve divided the evolution of AI into three release or periods – AI 0.5, AI 1.0 and AI 2.0.
AI 0.5: Birth, Research, and Invention
AI 0.5 includes the 1950’s and 1960’s for which I’ve noted some key milestones. Given the state of computing at this time, AI 0.5 consisted primarily of early research offering ways to represent problems they were trying to solve, the invention of various tools, languages and techniques, and of course, the first gathering of AI scientists. I’ve labeled this phase a 0.5, essentially a Beta, because on the whole, AI wasn’t ready to be commercialized – it was too expensive, too slow, and the prototypes weren’t scalable.
The First Intelligence Test – The Turing Test (1950)
 Enigma Machine – Source:Wikipedia
Enigma Machine – Source:WikipediaAlan Turing, also known for heading the team that broke the WWII German encryption machine Enigma, proposed a simple test to determine if a machine was intelligent. Called the Turing Test, this was a variation of the imitation game which was also the name of a recent movie detailing the effort to crack Enigma. In the imitation game, player X exchanges notes with two unseen players – one male and one female. Based on those interactions, player X would determine which player is male and which is female.
For the Turing test, player X interacts with the two unseen players through a computer terminal except one of the players is a computer. The goal of player X is to determine which player is a computer and which is human. To appear as a human, the computer would have to understand natural language, converse on a wide variation of topics and most important of all, understand the subtle nuances of human languages – definitely an aspirational goal given the state of computing at the time. No program would come close to passing the Turing test until ELIZA in 1966 (more on that later).
Early Research in Machine Learning
Minsky’s Neural Net Machine (1951)
In 1949, Donald Hebb proposed how neurons in the brain might learn when he published The Organization of Behavior. Two years later, Marvin Minsky and Dean Edmund built one of the first neural nets called the SNARC (Stochastic Neural Analog Reinforcement Calculator). The machine, about the size of a grand piano, consisted of 40 randomly connected Hebb synapses. Using a capacitor to hold the weighting of each synapse, each synapse was trainable – that is, the weightings were adjustable and determined if a signal less or more likely to propagate further. When the machine issues the right answer, the operator could reward all synapses that fired, thereby increasing the weight and the likelihood that that neuron would fire again. Any synapses that didn’t get rewarded naturally decreased weighting since the capacitor slowly lost its charge. Each synapse was about the size of two stacked keyboards and consisted of vacuum tubes and capacitors. In this interview with Marvin Minsky, you can hear Minsky recount the history of SNARC as well as see one of these synapses.
Rosenblatt’s Mark I Perceptron Machine (1957-1959)
 Perceptron Machine – Source:Wikipedia
Perceptron Machine – Source:WikipediaWith funding from the Office of Naval Research, Frank Rosenblatt at Cornell Aeronautical Laboratory created a large single-layer neural machine designed for visual pattern classification. The Mark I Perceptron has an input of 400 photocells (20×20 pixel image) that could connect to a layer of 512 neurons which could then be connected to eight output units. The connections between the inputs, the neurons, and the outputs could be dynamically configured with a patch panel so his team could try different models and learning algorithms. The Mark I reportedly took up six racks or 36 square feet and currently sits in the Smithsonian Institute.
For the time and the available technology, both Rosenblatt’s and Minsky’s research were remarkably creative and resulted in the first computers capable of learning through trial and error. While the Perceptron’s input of 400 pixels seems insignificant to the 2 million pixels in a 1080p HDTV display, it was still impressive given that most computers of the time didn’t even have monitors.
Heuristics, List Processing and Reasoning as Search – Logic Theorists (1955)
Herbert Simon, Allen Newell and John Clifford Shaw wrote a program to solve mathematical proofs when they created the Logic Theorist – arguably the first AI program written. The Logic Theorist was successful on many fronts including solving 38 of 52 mathematical theorems and introducing some new AI foundational concepts – heuristics, list processing, and reasoning as search.
With the understanding that intelligence or reasoning is a smart search, they used a search tree to represent a hypothesis (root) and logical deductions (each branch). Applied enough times, the proposition or solution was somewhere in the tree and the path to the proposition was the proof.
Since search trees can grow exponentially resulting in a combinatorial explosion which can become impractical to search, they used rules of thumb or heuristics to reduce the search space or prune any potentially fruitless branches. We’ll see a checker’s example of combinatorial explosion in the next section.
Finally, in trying to represent search spaces and to support the application of lists of deductions on this search space, they created a new programming language for list processing called Information Processing Language (IPL). The concepts in IPL served to be the foundation of the primary AI research language in AI 1.0 – LISP.
AI and Gaming – First Checkers Program (1951)
 Manchester Mark I – Source: Wikipedia
Manchester Mark I – Source: WikipediaIn early 1951, Christopher Strachey wrote the first checkers program in the UK at the National Physical Laboratory. Unfortunately, the Pilot ACE (a Alan Turing designed computer) his program ran on, ran out of memory (128 x 32 bit words). Later that year, Strachey ported his program to the Manchester Mark I (4,352 x 40 bit words) and ran it successfully. For comparison, this Mark I’s 20KB of memory (40 bits = 5 bytes, 5 x 4K = 20K) is a millionth of the memory found today’s computer memory (8GB RAM) or a trillionth compared to the today’s hard disks (1TB).
As it turns out, choosing your next move based on all possible moves so that you’ll win a game is similar to solving a mathematical proof. From your current position or base of the tree, branch out with all the possible moves – say eight moves or outcomes. Off of these branches, create another set of branches based on your opponent’s possible moves – say eight more. To keep the math simple, we’ll assume that there are only eight possible moves at each turn. At this point, the ends of the branched (or leaves) would represent all the possible outcomes after two moves – eight for the first and 82 or 64 outcomes for the second.

Any search space after four turns and only eight possible choices each turn
If you repeat this approach enough times, you’d have a tree that shows you all the possible scenarios including those which favor you the most. Unfortunately, after 10 moves (810) you’d have to look through more than one billion possible outcomes to determine the best possible path. As you can see, this simplistic approach requires extensive storage and computing power. While the first couple of moves would result in a manageable number of outcomes, each subsequent move multiplies the number of possible positions resulting in an exponential explosion.
The intelligence in gaming or any search space is in choosing what branches to explore and not to explore – i.e. essentially pruning the tree to minimize the search space. That’s what the Logic Theorist did successfully.
Checkers is Solved Through Brute Force
For checkers, in 2007, the Chinook computer at the University of Alberta actually calculated all the possible moves – 500 billion billion possible combinations in checkers (500,000,000,000,000,000,000). This took 18 years and more than 200 processors to calculate, but by knowing all the possible moves and their possible outcomes, Chinook will never lose a game of checkers. Obviously, this brute force method is not possible in most applications. For example, after 16 moves in Sudoku, there are 5.96 x 1098 possible outcomes, five times the total possible outcomes in checkers.
Like the rest of AI 0.5, these AI games were more proof of concepts than deployable solutions. They weren’t fast and didn’t win competitively. As we’ll see in AI 2.0, with faster hardware and in some cases, newer software techniques (i.e. neural networks), that would all change.
Birth of AI – The First AI Conference (1956)
The term Artificial Intelligence is widely attributed to John McCarthy in 1955 who organized the first ever AI conference in 1955. Along with notable heavy hitters like Marvin Minsky, Nathaniel Rochester from IBM, and Claude Shannon from Bell Labs, the group spent a couple of months at Dartmouth College exploring topics such as Natural Language, Neuron Nets and Self-Improvement (or Self-Learning).
In many ways, this first AI conference was aspirational as they understood that “the speeds and memory capacities of present computers may be insufficient to simulate many of the higher functions of the brain…” To put computer hardware in perspective, computer memory on $100K research computers was measured in single digit kilobytes and was stored on relatively slow spinning magnetic drums. That’s less than a millionth of the storage available on a 32GB thumb drive available for about 12 USD today.
For comparison, 1956 was the same year that researchers at MIT started experimenting with direct keyboard input into computers. For the time, the typical inputs were cards or paper tape which were punched on separate machines and then fed into the computers.
Foundational Language for AI Research – LISP (1958)
LISP stands for LISt Processing and would turn out to be the primary language for AI research in the 70’s and 80’s. Invented at MIT by John McCarthy, it carried on the innovations (list processing and recursion) of IPL at RAND while adding automatic memory management (including garbage collection) and self-modifying code.
List processing is important to AI as it allows programmers to easily store data in collections of lists and nested lists and apply operations wholesale to every item or atom in these lists – kind of like Microsoft Excel spreadsheet formulas working with every cell in a row or column. In fact, Lotus 123, the predecessor to Excel, was written in LISP. The ease with which one could apply operations to lists and sub-lists along with automatic memory management for the programmer, a somewhat administrative task, allowed AI researchers to focus more on the current problem making this an attractive language.
How LISP Works with Search Spaces
Consider the checkers example from earlier. If you have a list of 64 outcomes after two moves, to get all the possible outcomes after three moves, you would only need to apply all possible choices to that list of 64 moves. Repeat this same step with the 512 outcomes after three moves and you have your list of possible outcomes after four moves. Since LISP was designed for List Processing, this meant that researchers could focus on the important aspects of their program – how they determine which outcomes to explore and how to determine the next possible outcomes rather than the administration of these lists.
Finally, the list structure was used to represent both the data and the code, so writing a program that modified itself and then self-executed that modified code opened up some interesting types of applications. Known as Symbolic Programming, this code effectively allows programs to learn from the past, self-modify, and then execute the new behavior.
In the 60 years since its inception, the LISP language has had over 20 dialects created and as part of AI 1.0, several companies even architected computers, LISP Machines, to run this language optimally. For more on the development of LISP, see McCarthy’s recount in 1978 or check out the full history of LISP on Wikipedia.
The First Expert System – DENDRAL (1965)
Written in LISP, the DENDRAL was an early expert system that helped organic chemists identify unknown organic molecules. With spectrographic data for the substance, DENDRAL would produce a set of possible chemical structures with performance that rivaled expert chemists.
Developed by Edward Feigenbaum and his team of Stanford researchers, DENDRAL was notable for many firsts including being the first rules-based expert system used to address real problems. DENDRAL is known for its novel approach for storing rules. Whereas previous expert systems intertwined the knowledge and heuristics with the program that used that knowledge, DENDRAL separated the domain-specific rules into a knowledge base and the reasoning mechanism into an inference engine. This architectural separation would allow rules or the knowledge to be easily defined and edited without the risk of breaking the reasoning code. Additionally, this also allows changes and improvements to the inference engine without unintentional changes to the rules.
This architectural separation would also be the basis of many successful commercial expert systems and decision support systems in AI 1.0 where these companies could focus on providing fast and efficient inference engines. The customers of these expert system shells and their Knowledge Engineers, could then focus on understanding the domain and writing rules.
The Turing Test and Natural Language Processing – ELIZA (1966)
Written by Joseph Weizenbaum at the MIT AI Lab, ELIZA is one of the first notable AI programs capable of passing the Turing test. Modelled after a Rogerian psychotherapist, ELIZA created an illusion that it understood you by pattern matching your responses, finding the subject or object of your statement, and using them in Mad Libs-like responses. The result was not unlike a conversation you might have with your therapist as you can see in this implementation from Cal State Fullerton. Alternatively, you can try out ELIZA yourself at med-ai.com.

As you can see from the example, ELIZA understands sentence structure enough to use parts of my statements in her responses and frequently, defaults to simple open-ended questions. ELIZA has no understanding of what you’re really saying. By playing the role of a psychotherapist, it didn’t have to understand general topics like a modern-day IBM Watson . That said, at the time, many still believed ELIZA was intelligent and in the case of Weizenbaum’s secretary, she reportedly would confide in ELIZA.
First Humanoid Robot – WABOT-1 by Professor Kato Ichiro at Waseda University (1967-1972)
Kato Ichiro led the development of the first intelligent humanoid robot. What differentiates this robot from others is both its human form and the multiple systems used for control and intelligence.
While early electronic autonomous robots like Johns Hopkin’s 1960’s Beast and William Grey Walter’s 1948 Elmer and Elsie (ELectroMEchanical Robot, Light-Sensitive) were impressive for their time, they were relatively simple robots. Elmer and Elsie were turtle-like robots that used light and touch for guidance. Even earlier, Da Vinci’s knight was humanoid in form, but was only mechanical and anything but intelligent.
Several centuries after Da Vinci, in 1970, WABOT-1 seems significantly more human-like with multiple systems for vision, hearing (language understanding and speech), limb control (balance and movement) and hand control (tactile sensors). While not as agile as the door opening robotic dogs built by Boston Dynamics or as conversational as Hanson Robotic’s Sophia, WABOT-1 did walk and interact in Japanese providing us with a preview of modern humanoid robots.
Neural Network Research Stalls – Perceptrons by Minsky and Papert (1969)
In 1969, Marvin Minsky and Seymour Papert published Perceptrons: An Introduction to Computational Geometry that mathematically analyzed a type of neural network called the Perceptron (Rosenblatt). Essentially, the critique centered around the single layer of neurons, the need for multiple layers and the inadequacy of learning algorithms to address multiple layers. Their conclusion that there were severe limitations with what we now know as deep learning. This publication influenced the AI community and resulted in directing AI research away from Neural Networks and Machine Learning until the 80’s.
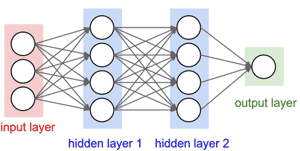
Single Layer Neural Net versus Multi-Layer Neural Net
Having multiple layers for neural networks is critical to intelligence and how we think and manipulate information. Each layer of a neural network allows us to abstract what we know. For example, when we recognize a face in an image, we don’t derive this directly from the light seen by the rods/cones in our retinas. There are many steps or abstractions that occurs. Light detected by the rods/cones are grouped and abstracted into lines of different angles which becomes different shapes which becomes facial features (nose, eye) which places together in the right position becomes a face. Each of these abstraction steps require one or more layers. Any layer that isn’t directly connected to external inputs or outputs are typically known as hidden layers.
In psychology, this process of abstraction is called Chunking. Chunking in its most simplistic form is the use of terminology that allows us to more easily communicate. Would it be easier to say that “thing on four wheels that we sit in and drive from point A to point B” or would it be easier to just say the “car”? Without chunking, we simply couldn’t have a normal conversation without everyone losing their patience. With neural networks, each layer allows previous conclusions (e.g. a point, a line, an oval) to be grouped and used to reach new conclusions (e.g. a nose or an eye). Results of chunking can be chunked further – e.g. lines, points, ovals becomes nose and eyes which becomes a face.
AI Winter
“AI Winter” was first coined at the 1984 AAAI (American Association of Artificial Intelligence) annual meeting where Marvin Minsky and Roger Schank warned of the down cycle that would follow the unrealistic expectations and hyper-enthusiasm for AI in the 80’s. They started to see the boom and bust cycle repeating itself in the 80’s as they had lived through the optimistic and well-funded 50’s and 60’s followed by the pessimistic and waning interest (and funding) of the 70’s.
In the early years, optimism was rampant. Consider a 1956 quote from Herbert Simon (an AI researcher and Nobel Prize winner for Economics): “Machines will be capable, within twenty years, of doing any work a man can do.” Additionally, in the 1960’s some predicted the replacement of human translators within five years. Watch this “Thinking Machine” video along to hear some other amusing AI-related predictions.
In the 1970’s, researchers in the U.K. and the U.S. saw a dramatic decrease in funding from government resources (e.g. DARPA – their main source of funding). The recessionary 1970’s might share some blame for the first AI Winter, but most researchers attribute its cause to the hype and unrealistic expectations set during the earlier boom years. Given the hardware limitations of the time and the need to build tooling and new computer languages, it’s easy to see how the researcher’s software aspirations were light years ahead of current capabilities. Additionally, others would point to the 1969 Mansfield Amendment which stopped undirected research, and instead, directed research funding towards military-related applications. Regardless of the cause, for a time, there was disillusionment and a significant pause in AI research funding
AI 1.0: R&D, Enterprise, Expert Systems, AI Hardware
Whereas AI 0.5 was about research, birth, and invention, AI 1.0 follows up with more successful research and finally, commercialization. During this period, there will be more successes in software (e.g. expert systems, object-oriented programming, LISP), hardware (i.e. LISP Machines), and applications within the enterprise. Like many 1.0 products, it worked but only narrowly and there are still had remaining issues.
First Commercial Application of Expert Systems – Digital’s R1/XCON (1980)
Most early expert systems including DENDRAL and MYCIN (Stanford – 1972) were demonstrations or research projects, so when Digital Equipment Corporation’s (a.k.a. DEC or Digital), a leading vendor of minicomputers of the time, successfully deployed an expert system commercially, the AI community took notice.
Well before the age of standardization (“plug and play” drivers and connectors), configuring a computer for a customer included determining the right set of CPUs, memory, backplanes, cabinets, power supplies, disks, tapes, printers, cables, and the right software drivers for each of these. Configuring systems for customers fell to Digital’s salesforce, and they generally found this process problematic at best. With 30,000 possible configurations, costly mistakes were not uncommon with a delivery of a computer system without the right cables, print drivers or software resulting in lost time, and lower customer satisfaction. Field Service Engineers would either provide the missing items for free to appease the customer during installation or order the parts to be installed at a later time. In either case, significant time and money was lost or wasted.
To address this, Digital created the R1 or XCON (eXpert CONfigurater) expert system. Deployed in 1980, XCON was implemented in OPS5 (a rules-based programming language with an inference engine) and by 1989 contained more than 15,000 rules. XCON was in daily use at Digital as it configured more than 90 percent of all their computer orders (by value) resulting in a savings of $25M annually.
AI Heats Up Again – Japan’s Fifth Generation Computer Project (1982)
Between 1982 and 1992, Japan spent more than $400M as part of their initiative to create the next super computer or more commonly known as the Fifth Generation computer. This next generation computer included several important areas of investigation including expert systems. Japan’s Ministry of International Trade and Industry (MITI) initiated this effort to make Japan’s computer industry a leader rather than a follower as it had been in the past.
This initiative resulted in an increase in funding for AI research directly from MITI and indirectly from several other national initiatives. From 1982 to 1987, the British government sponsored the Alvey program where their focus included AI, Natural Language and Parallel Processing. Europe also responded with the European Strategic Program on Research in Information Technology (ESPRIT)
The US Government responded to this potential loss in leadership with the Strategic Computing Initiative (SCI). Detailed in Alex Roland’s 2002 book Strategic Computing: DARPA and the Quest for Machine Intelligence, 1983-1993, the US Congress was worried that Fifth Generation program “threatened to leap-frog the United States” and would “assume world leadership in high-end computing technology.” They even viewed this threat as “more alarming than Ronald Reagan’s evil empire (USSR -Russia).” Armed with this, DARPA spent over $1 billion dollars over the course from 1983-1993 in search of machine intelligence.
Additionally in the United States, a 12 company tech consortium called the Microelectronics and Computer Consortium (MCC) was created in Austin Texas. Due to the limitations of current anti-trust laws, MCC’s birth required an act of Congress in 1984.
While none of these national programs resulted in machine intelligence or a change in technology dominance, they did result in significant progress as they funded and collaborated with universities, research institutions, and commercial companies in AI related areas, such as Expert Systems (IntelliCorp), Lisp Machines (Symbolics), Autonomous Vehicles, Natural Language Understanding and Super Computers (Thinking Machines).
Dedicated Lisp Machines – MIT AI Lab (1973), Symbolics, LMI, and TI
 Symbolics 3620 (1987) at the Computer History Museum. The original 3600 from 1982 was the size of a refrigerator.
Symbolics 3620 (1987) at the Computer History Museum. The original 3600 from 1982 was the size of a refrigerator.Source: John Hsia
Invented in 1958 and used across most AI projects, it was clear that LISP was foundational to the future of AI. Unfortunately, the programming paradigm of symbolic language LISP was quite different than the popular procedural languages of the day (Fortran and Cobol) and the computer systems designed for them. As a result, LISP’s performance was slow on these traditional architectures and as a result, demanded significantly more CPU power and memory.
In 1973, the MIT AI Lab recognized this need for specialized hardware and started the MIT LISP Machine Project. Architected for LISP and coupled with an object-oriented LISP operating system, the second prototype of this machine, the CADR, was popular with hackers resulting in DARPA funding in 1978.
The CADR was commercialized through three different companies in the early 1980’s – Symbolics, LISP Machines Inc., and Texas Instruments. While each company made significant changes to the architecture and software environment, Symbolics ended up owning the majority of the LISP machine market.
From the early 80’s and into the mid 90’s, LISP machines were the primary platform for serious AI research, development and deployment. From expert systems to Intelligent CAD to massively parallel Connection Machines, LISP machines would play a key role in the development of these technologies during this time. As the performance of general computing platforms like Sun Microsystems, HP workstations, and other engineering workstations improved enough for LISP compilers to be hosted on these computers, the role of LISP machines diminished.
Specialized Hardware Wasn’t Just for AI
In the 80’s and 90’s, it was not unusual for computers to be specialized to run a particular language or address a specific type of problem. Xerox had their word processing computers – Xerox Star whose predecessor, the Xerox Alto, was the inspiration for the windows and mouse of the Apple Macintosh. Rational Software had their ADA computers as ADA was the standardized language for DOD projects. Silicon Graphics or SGI had their graphics processing computers. And Symbolics had the premiere Lisp Machine.
Object Oriented Languages, Steve’s Ice Cream and Birds
While most serious programmers today use an object-oriented programming language (Java, C++, C#, Objective C), that wasn’t the case in the 1980’s. During this time, most programmers were using some sort of functional or procedural language such as Pascal, Fortran, C or Algol. While they toiled to organize, coordinate and maintain how their data interacted with their functions within their programs, a lucky set of programmers with access to research computers or a LISP machine used object-oriented languages (OO) such as Flavors or Smalltalk, and let the language organize data and code interaction for them.
With OO languages, the programmer defines objects (e.g. birds, fish) with attribute (e.g. x-y location, speed, direction) and behavior (e.g. fly to, swim to). The behavior is the part that OO adds. The objects can discover or interrogate each other and communicate with or send messages to each other. So rather than the programmer having to coordinate the behavior amongst all the objects (a.k.a. classes), they just need to design the objects, so they can talk to teach other and they’ll become self-organizing.
For example, is when you right-click on a file in your file explore or browser and see a pop-up with different menu options depending on the type of file. As an example, a PDF file would show a “print” command while an audio or video file might show a “play” option. Under the covers, when you right-click, the window system doesn’t know what all the possible behavior is for all the types of file. Instead, the window system tells the file that a right mouse click occurred and the file responds with all the types of possible actions. Then the window system displays the actions. Realistically, there are more layers, but that’s enough for our purposes.
What Does OO Have to Do with Ice Cream?
Flavors was one of the early OO extension to LISP on the Symbolics LISP Machine. Developed by Howard Cannon at the MIT AI Lab, he got the inspiration for his naming constructs from Steve’s Ice Cream in Boston – just down the street from the AI lab.
When you order ice cream at Steve’s, you select a base flavor (say vanilla). Then, you select from various mix-ins (say Oreos) which they promptly mix together to create a specialized flavor. The new flavor has a new set of characteristics (vanilla bean and chocolate) and behavior (crunchy) resulting from the combination of base flavor and from the Oreo mix-ins. If you wanted to create another flavor of ice cream with chewiness and strawberry taste but still have the characteristics of the new flavor you just created, you’d add more flavors (strawberry) and mix-ins (gummy bears).
Believe it or not, this describes the OO concept of inheritance from classes/flavors (deriving characteristics and behavior from a base flavor) and the injection of new behavior via mix-ins. Flavors, the LISP Object Oriented Programming Language found on Symbolics LISP Machines, goes a step further and uses these terms verbatim.
Using a programming example, if you wanted a window with a scroll bar, you would just add a scroll bar mix-in to a base window class or flavor. Now, you have a new flavor/class that you can use as is or as a base flavor/class with other mix-ins and other flavors.
How OO Helped Animate a Movie – Birds Flock and Fish School
Imagine a computer animation where the character animated itself. Using object-oriented programming techniques and a distributed behavioral model, Craig Reynolds from the Symbolics Graphics Division, had the extras in an animated short determine their own behavior. By adding behavior to birds to stay together as a flock while avoiding obstacles (e.g. each other and the ground), the animators at Symbolics could create natural-looking flocking and schooling (fish) behavior. This approach freed the animators from having to micro-manage the behavior of every movie extra. Instead, this allowed the animators to focus on the detailed movements of the main characters while still getting natural behavior in the background. At most, the animator only had to provide a general direction to the flock.
You can see the results of this research in the schooling behavior of the fish and the flocking behavior of the birds in the computer animated short Stanley and Stella (debuted at Siggraph 1987). Contrast this animation with Pixar’s 1987 computer animated short Red’s Dream (or their earlier 1986 short Luxo Jr), which also debuted at the same conference. While well-scripted and entertaining, neither Pixar short had any extras, just the main characters, and every action was deliberately scripted by the animators.
The Leading Expert System Shells of the 80’s – ART and KEE
Inspired by Digital’s success with expert systems and with the promise that they could replicate their domain experts, many governmental agencies and commercial companies started applying expert systems to a wide variety of problems. To support this at scale, several commercial companies developed expert system shells. Expert system shells are essentially an expert system with the rules removed. The inference engine is still intact, so your organization only needs to define the rules for your domain. Two of the leading LISP Machine expert system shells were ART (Automated Reasoning Tool) from Inference Corporation and KEE (Knowledge Engineering Environment) from Intellicorp. With these shells, the Knowledge Engineer only needed to focus on interviewing the domain expert and then codify that logic into rules (if-then statements for the purposes of this blog).
American Express’ Authorization Assistant (1988)
One notable commercial deployment of ART, which I had the opportunity to see in action, was the American Express (Amex) Authorization Assistant (AA). At Amex, credit card approval isn’t as simple as approvals at their competitors, Visa and Mastercard, where the credit limit is the primary concern. With no credit card limit, Amex used a series of business rules to approve or deny a transaction. For those questionable transactions, approval was usually referred to a human agent who made the call. To expedite the decision process for these questionable transactions, Amex used the Authorization Assistant as an advisor where AA would recommend a ruling to the agent. Since expert systems know which rules fired to arrive at the recommendation, the agent received reasons along with a recommendation.
For example, if an infrequently used credit card suddenly starts being charged with big ticket items (e.g. computers, cameras) that can be easily resold on the black market, then AA would recommend denying the transaction or asking for identity verification. If a similar card with minimal purchases suddenly sees big purchases in a country where they don’t reside, the purchase should be questioned as well. But if that same card saw travel-related purchases like rental cars, airline tickets or hotels proceeding the questionable charge, it probably wouldn’t be questioned as that’s likely the card owner vacationing. Finally, if the card holder is a celebrity or a high-level government official, the purchase is less likely to be questioned at the risk of embarrassing them or creating an embarrassing story they might relay on national TV the next time they’re on a talk show.
Revival of Neural Networks – Backpropagation and Deep Learning
Despite all the AI focus on Symbolic processing and expert systems and the setback resulting from Minsky’s critique in his Perceptron book, research on neural networks continued. Minsky had brought to light the need for multi-layers of perceptron’s and the shortcomings of learning algorithms of the day (only worked for one layer). A learning algorithm is effectively how a neural network or deep neural network self-trains for a particular task.
In 1974, Paul Werbos was the first to propose using Backpropagation to train multi-layer neural nets after studying it as part of his PhD thesis – “Beyond regression: new tools for prediction and analysis in the behavioral sciences.”
Single Layer Learning versus Multi-Layer Learning
With a single layer, training simply meant changing the weighting of the connections and the neuron that resulted in the positive or false outcome. There’s only one layer so there’s only one set of neurons responsible.
With multiple layers, the neurons (i.e. layer X) directly connected to the output isn’t the only neuron responsible for the outcome. There are hidden layers (i.e. layer X-1, X-2 …) whose outputs caused the last neuron to fire. Since these hidden layers were partly responsible for the last neuron to fire directly (X-1) and indirectly (X-2 …), it makes sense to strengthen (correct answer) or weaken (wrong answer) those connections as well. Backpropagation basically starts at the output and works backwards towards the input. It adjusts the settings for the previous layer and repeats this for each successive hidden layer until the input layers are reached.
Despite his promising proposal in 1974 and Werbos’ effort in shopping his ideas around MIT, Harvard and with Minsky, there was no interest. This was four short years after Minsky’s critique in Perceptrons so the chilling reception he received was not surprising.
Interest in Neural Networks will revive about a decade later after Werbos’ findings were rediscovered and published in 1985 by Parker and in 1986 by Rumelhart, Hinton and Williams.
R&D … & S – Research and Defense and Space
While AI 1.0 was kicked off by the worldwide response to Japan’s Fifth Generation Computer Project (1982), it was sustained through the 1980’s because of government spending on defense and the space program.
In 1983, in the midst of the Cold War, Ronald Reagan announced the Strategic Defense Initiative (SDI) also known as “Star Wars.” This initiative resulted from years of a stalemated Cold War and the frightening policy of Mutually Assured Destruction (MAD). SDI started with research into different approaches for a defensive shield made up of ground and orbit-based missile system for protecting the United States from Russian missiles. Given the technical difficulty of intercepting missiles and with increased spending on all thing defense including intelligence gathering, AI along with many other aspects of Computer Science benefited. During this time, numerous defense companies were researching applications of AI for autonomous vehicles, battle management systems, pilot assistants and filtering intercepted communication. While it’s unclear how many of these resulted in actual deployment, there is no doubt that funding helped advanced AI fields such as voice recognition, natural language understanding, machine vision, planning and image recognition.
At the same time of the defense build-up, the US space program was also going through its own resurgence. The Space Shuttle Columbia began orbital flights in 1981 followed by additional shuttles – Challenger, Discovery and Atlantis in 1983, 1984 and 1985 respectively. With 24 missions in little over five years, it seemed like space flight had become routine. While the Space Shuttle itself was inspiring a whole generation, the real goal was Space Station Freedom. Announced in 1984 by Ronald Reagan, this space station project would ultimately become the International Space Station (ISS) orbiting the planet now. Between Freedom and the Space Shuttle, there were many potential applications for AI.
Space stations are very complex and since there would be a minimal crew on board, there would be a need for automated systems to maximize the effectiveness of the small crew. From expert systems to reorient the station to avoid deadly space debris to general needs for diagnosis system malfunctions, having an expert system on the station was the next best thing to having the expert there in person. If you’re curious, just search the NASA data base for “space station expert systems” and you’ll see the thousands of space station expert systems.
The expert system needs for the Space Shuttle, such as mission and payload planning, were just as numerous. Like Freedom, having access to experts in space or at mission control was indispensable. From navigation to launching to docking to reentry, there were thousands of applications.
CIMON – Crew Interactive Mobile CompanioN
The need for experts and on-site help in space continues today. On June 28, 2018, a “Flying Brain” blasted off on a Falcon 9 rocket towards the International Space Station. This flying, AI assistant robot will float in zero gravity and propel itself towards the astronaut when called to help with experiment procedures.

AI Winter again
As Minsky warned in 1984, too much hype and over exuberance would result in a second AI Winter. While this may have contributed to a second AI Winter, there were a significant number of other causes as well.
General Computing Catches Up With Lisp Machines
During the mid-1980’s, the Symbolics Lisp Machine was the darling of the AI Boom. With hardware and software designed from the ground up for Lisp programmers, it’s no surprise that these $100,000 computers flourished. When the Lisp machines first came out, the hardware ran Lisp faster than any general computer could. More importantly, the software development environment was finely tuned to maximize the productivity of each highly paid AI researcher or Lisp Programmer. Speaking from experience, developing software on the Symbolics with its high-resolution monitors, optical mouse and Lisp debugging environment was like driving a Porsche down the hairpin turns of Pacific Coast Highway – it just felt right.
As the 1980’s progressed, LISP and expert system shells became available on non-specialized computers like those of Sun Microsystems, HP and IBM. Coupled with the significant performance improvements they were making through the use of chips using RISC (Reduced Instruction Set Computers) architecture, the economics of using Symbolics and other Lisp Machines became less compelling. This change was reflected in reduced sales across Symbolics, TI and LMI. In 1987, LMI went bankrupt. Subsequently, in March 1988, Symbolics announced its third round of layoffs reducing its workforce by over 1/3. Unfortunately, this would not be its last layoff as AI Winter set in.
Standardization of LISP Allows Development and Deployment of AI on Standard Hardware
It was not uncommon to research and develop an AI system in one dialect of Lisp on a high-end Lisp Machine only to have to deploy on a lower end computer with a different dialect of Lisp. With multiple OO languages and with over 20+ dialects of Lisp, the porting effort was usually significant. To address this shortcoming, the ANSI Common Lisp language was created in 1984 and in later versions would even include object oriented techniques through the Common Lisp Object System (CLOS). This standardization allowed more and more AI systems to be developed on non-AI computers because Common Lisp became just another standardized language running on a standard piece of hardware.
Deployment Drives AI Systems Towards Traditional Languages and ADA
As military systems finished research and considered deployment, the memory, power and cost constraints of deploying in an embedded environment or in a hardened environment such as the Space Station, a fighter jet cockpit, or an armored vehicle became an issue. In an attempt to address these issues, Symbolics did miniaturize their specialized CPU into a “Lisp Chip” and NASA even looked at hardening it for space. Unfortunately, between the standardization of ADA for DOD projects and the strategy of using Expert System Shell that compiled into standardized languages, Lisp Machine never broke out of its role as a research and development machine. This was not lost on companies like Intellicorp and Inference Corporation who came up with ADA version of KEE and ART.
A Frozen O-Ring and a Warm Wall
Two macro events also caused a reduction in AI spending – freezing conditions that caused the failure of an O-Ring on the Space Shuttle and warming conditions that brought down a wall.
On an exceptionally cold morning of January 28, 1986, the Space Shuttle Challenger launched from the Kennedy Space Center in Coco Beach, Florida. Due to the effects of unusually cold conditions on critical O-Rings, what started as a routine mission turned into a spectacular and deadly explosion 73 seconds into the launch taking the lives of seven brave astronauts. The investigation, design and procedural changes that followed resulted in a three-year delay that further delayed the Space Station and much of the Expert System and AI work around it.
Early in 1989 the relations between the United States and the Soviet Union began to warm and gradually, Eastern European communist dictatorships fell one by one. On November 9, 1989, East and West Berliners were allowed to freely cross the Berlin wall and by the following weekend, citizens were tearing down the wall brick by brick. Within a year, East and West Germany was unified. This marked the end of the cold war and it also marked the end of the military buildup and the funding of AI projects that goes with it. The DOD giveth and the DOD taketh away.
Fifth Generation Computing Project Abandoned in 1992
Ten years and $400 Million dollars later, Japan’s Ministry of International Trade and Industry abandoned its goal of developing computers with reasoning capabilities. Japan’s initiative forced US, Europe and the UK to respond with their programs. While the combined worldwide effort didn’t result in the sought-after breakthroughs or any significant change in the balance of power (technology wise), it did push Computer Technology and AI further along than it would have been otherwise.
Was It Really an AI Winter?
While some high-profile AI companies suffered some significant setbacks, this did not diminish the value of individual AI technologies that saw commercial or enterprise success. To help shed the negative concerns of AI Winter, many rebranded themselves and continued to evolve. Expert systems became Knowledge-based systems and Intelligent Decision Support Systems. Intelligent CAD became known as Knowledge-Based Engineering. Also as AI-focused computers such as Lisp Machine fell out of vogue (and the big specialized hardware budgets to support them), many of the Lisp environments and Expert Systems shells simply ported their solutions to standard workstations and standard languages. Albeit, while the AI fervor settled down, the work continued on.
AI 2.0 – Neural Networks and Democratization of AI for Everyone, Everywhere
While it’s still early in this release of AI, it’s clear that AI is exploding once again and this time, it’s everywhere and accessible by everyone. From our smartphones to self-driving cars to home appliances, we’ll find claims of AI tech improving performance or enhancing our experience in some way. It’s hard to turn a corner without being hit by a headline about how AI will take our jobs, destroy our planet or make our lives better.
I’ve title this era AI 2.0. One major point of differentiation between AI 1.0 and 2.0 was the technology that the two eras focused on. The golden boy of AI 1.0 was expert systems whereas, for AI 2.0, it’s neural networks.
Like any 1.0 product, AI was starting to become commercialized but with limited success. On the other hand in 2.0, AI worked out many of 1.0’s bugs partially helped along by more capable and less expensive computers. It’s now economically feasible, more scalable and as a result, it’s being applied everywhere.
“The AI” is now a term
In AI 1.0, technologist used terms like “The Expert System” or “The Speech Recognition Program” but never referenced “The AI”. They might have said, “The system uses AI technology to solve …” but not “The AI solves …” These days, it’s common to hear “The AI” did this or “The AI” did that.
We might just attribute this to today’s need for brevity, but imho and fwiw, it might be the increased complexity of systems and the multiple AI technologies used. For example, a smart speaker uses multiple AI technologies (voice recognition, speech recognition, language understanding, language translation, neural networks) and would be hard to describe other than to aggregate the multiple AI components as “The AI.” Regardless of the origin, you’ll now see the term “The AI” to refer to any product or service or any part of a product or service that appears to have some intelligence in it.
Democratization of AI through Moore’s Law, Cloud Services and Mobile
In AI 1.0, most AI systems were Enterprise systems (e.g. Digital’s R1/XCON, American Express Authorization Assistant) so most people never interacted with an AI directly. For AI to touch everyone directly, the devices or computers that hosts the AI must be:
- Easily accessible to more people by being affordable and by being smaller (laptop or mobile devices)
- Capable of hosting the AI by either being fast enough or have a fast-enough connection to consult a remote and more powerful AI (Cloud Services)
Smaller, Cheaper, Faster and Mobile
For AI to be accessible, the hurdles to owning a computer must be removed. Having computers in classrooms and libraries increases accessibility over just having them in businesses. And, as we all started discovering in the last decade since the launch of smartphones in 2007, the ultimate accessibility is having a powerful computer in your pocket.
A perfect example of the miniaturization in cost, power and the jump in power is the smartphone. In Mikal Khoso’s 2016 Northeaster University article, Mikal equates a 2016 smartphone all of NASA’s computing power when they put the first man on the moon. Of course, comparing what the Apollo 11 mission in 1969 to your 2018 smartphone isn’t the fairest of comparisons but they are fun. Let’s look at the Apollo guidance computer versus the Samsung Galaxy S9:
- Guidance computer had a 1 MHz 16 bit processor vs the S9’s 2.8 GHz 64 bit (counting all 8 cores of Qualcomm’s Snapdragon 845)
… that’s 11,200 times faster (when we take the word size into consideration) - 4 KB vs 4GB RAM
… that’s 1,000,000 times more memory - 1800 cubic inches (24 x 12.5 x 6 inches – about the size of a bluray player) vs 5.2 cubic inches (147.7 x 68.7 x 8.5 mm – about the volume a pack of cigaretts)
… that’s 3% of the size - 1 lbs (no touchscreen included) vs 163 grams
… that’s 0.5% of the weight (163/31,796)
Again this is not a fair comparison for the Samsung Galaxy S9, since the Apollo computer was custom built by MIT, only did one thing and costs a lot more than $110 (that’s 1969 dollars for the S9’s $720 retail cost today). Plus, the S9 is a general purpose mobile computer that communicates wirelessly at 4G speeds, records 4K video and contains its own power source.
While this is extreme, the comparison between technologies of the 1980’s and today shows significant advances as well. Just look at the cost of a 286-based PC with EGA color monitor in the late 1980’s (about $2,000 if you built it yourself) versus a mid-range 8″ tablet from Samsung (Galaxy Tab A – $230). Between the displays (640×350 with 16 colors vs 1024×768 with 16M colors), the processors (eight fast cores versus one slow core), the memory (GigaBytes versus MegaBytes) and the size, the computing capabilities have become much more affordable and accessible now than ever.
All the miniaturization of components, processors, memory and wireless antennas has put small, connected computers or if you will, IoT devices (wearables, AR glasses) and sensors everywhere at relatively affordable costs. Just count all the devices you use every day to gain an idea of how accessible they are – fitness tracker, smartphone, home smart thermostat, TV, car, smartwatch. All these devices mean that there are many more opportunities where AI can come into play.
Easier to Build and Maintain – Cloud Services and Web Services
The cost of computing isn’t just about the cost of the hardware. There’s significant time, energy and cost in architecting, designing, developing, deploying, maintaining and scaling the software solutions that we use. Two major developments since AI 1.0 that has helped significantly reduce these costs are Web Services and Cloud Services.
Web Services
Web Services are remote calls made over the web to access functionality someone else might already be doing or might do better. This typically means that you can focus on your application rather than more general task.
For an example, let’s take a look at calculating sales tax – a surprisingly complex task to maintain. For your e-commerce website, to calculate sales tax on its own, you’d have to take into consideration the type of product or service sold, the customer’s state, county and possibly municipality. You’d also have to track the ever-changing taxation laws at the state, county and municipality level.
If you used web services, your website can just make a simple RESTful request or a SOAP call. You’d provide the type of product or service, area code and possibly address, and voila, the web service would return the current tax rate. You might have to pay to subscribe to that service, but you don’t have to pay a developer to develop and maintain that logic with the latest tax laws. This ability to delegate allows your team to focus on their app while still reducing costs and still delivering an overall solution faster.
For AI, Web Services means more reuse. If someone else has already done the research for facial recognition or voice recognition or natural language understanding, you don’t have to. You can just add your piece of the puzzle and let someone else take care of the rest. If you happen to have a great language translator then let the pre-trained services such as Google Natural Language and Google Speech API take care of the rest. You can even gain access to proven, Jeopardy winning AI that you otherwise couldn’t such as IBM Watson.
Cloud Services
Cloud Services goes a step further and allows you to host your data or your program on someone else’s hardware. With cloud services, if you’re putting together an online service, you don’t have to buy the servers, hire the computer system operators and lease out the space. Now through services like Amazon Web Services, Microsoft Azure, or IBM cloud services, you can dynamically host your program in as many servers as you need when you need it and only have to pay for what you use.
If you detect an increase in demand, you only need to request that additional computing power or that storage as you need it. Most cloud services will be able to address your request almost instantly, so you can still handle that unexpected demand without having to invest in idle capacity. Additionally, there is no significant start-up cost or long lead times typically associated with setting up data centers and hiring and training staffing.
For AI, cloud services means access to proven machine learning frameworks, so you can train your own AI and then host that trained AI for others to use (or for others to subscribe to) without buying hardware, hiring computer operators or leasing server space.
With web services, cloud services and mobility, your AI service can be hosted on a super computer so that it’s accessible from your app on smartphones. The mobile app would call various AI web services including prebuilt ones or yours hosted on a cloud service.
Focus on Neural Network
In the AI 2.0 era, the democratization and accessibility of computing resources has addressed the computationally intensive nature of neural nets. Additionally, during AI 2.0, three additional ingredients have come into play to put Neural Networks back on track. The three ingredients are the availability of large amount of data needed to train neural nets, the breakthrough in deep learning and the speed gains in using GPUs.
Ingredient 1: More Available Data for Training – Internet, Smartphones and IoT
One of the unintentional consequences of the internet and of being constantly connected through mobile devices is the plethora of data available. Data is essential to training neural networks, that is, to train a blank neural network with zero knowledge into an AI with expertise, image recognition or the ability to predict or to advise. Data for an AI is not unlike the real-world experiences and teachings that differentiates a child’s mind from a newborn’s mind.
Before the internet, computers were either used in the enterprise (including government) or with standalone desktop applications such as Lotus 123, Turbo Tax, Quicken or an encyclopedia app. While enterprises and government entities might have shared data within their organizations, the information in standalone PC applications generally stayed with the applications. Essentially, whatever happened in those apps stay in those apps.
The Internet
With the internet, now websites like Amazon, YouTube, Facebook and others have such an enormous amount of data that can be used for predictive and user behavioral analysis such as recommendation engines. But these PCs and laptops weren’t truly mobile so they weren’t always on and didn’t see into all aspect of our lives – they still sat at home or at a coffee shop.
Smartphones
In the last decade, smartphones have dramatically amplified this growing amount of Big Data. With over 2.5 billion smartphones in our back pockets, there is little we do or think that isn’t tracked by our smartphones. Undoubtedly, there is an enormous amount of data that results from apps tracking where we go, what we eat, who we friend, what we communicate and what we look for.
IoT
Add to that as many as 10 billion IoT devices such as cars, smartwatches, smart speakers and home security and the volume of generated data becomes incomprehensible. Not only does this data become useful for training AI systems, the reality is that the volume of data is impossible to use or comprehend without AI. One doesn’t have to look far for free, open data sets for training your AI for image, natural language or speech processing or free data sets from government agencies.
Ingredient 2: Deep Learning Breakthrough – Backpropagation, Hinton and Computer Vision
Learning, i.e. teaching or training a neural network, involves examining the output produced by the neural net versus the desired output, and then adjusting the weights or states of the connections with the intention of getting closer to producing a correct answer. Deep learning is this same process but for deep neural nets – i.e. neural nets with hidden layers. With deep neural nets, the correction needs to be distributed through all the hidden layers and paths that helped select the right or wrong answer – not just the ones close to the results. As pointed out in AI 0.5, Minsky’s 1969 paper on Perceptrons concluded that the learning algorithms available at the time didn’t address deep neural nets.
In 1982, John Hopfield created a recurrent ANN, Hopfield Network, used for storing and retrieving memories. Later in 1986, Geoffrey Hinton, David Rumelhart and Ronald Williams published “Learning representations by back-propagating errors” which addressed the issue of how to teach multi-layer neural networks. While applying backpropagation to neural networks was not a new concept, Hinton was more successful in “concisely and clearly” communicating the use of back propagation then predecessors such as Linnainmaa in 1970 and Werbos in 1974 and 1982 and David Parker in 1982. That said, we were still in the heart of AI 1.0 where Expert Systems were still seeing significant success and most AI research was directed away from neural networks as a result of Minsky’s 1969 paper. Hinton currently works at Google Brain and is a professor at University of Toronto.
One indirect result of this is research in 1989 by Yann LeCun at AT&T Bell Labs. He demonstrated a practical application of backpropagation to train a convolutional neural network to read handwritten numbers – as shown in this video. Ultimately, his work resulted in a 1990’s commercial application that reads the check amounts handwritten on 10-20% of all checks. From late 2013 to early 2018, Yann LeCun was Facebook’s Chief AI Scientist.
With research and practical applications from Hinton and others, AI started to get back on its original track from the early 1950’s – namely Machine Learning. Yes, there would be some significant milestones like Jonathan Schaeffer’s Deep Blue’s defeat of the world’s chess champion in 1997 but that victory was primarily a result of sheer muscle and not based on neural networks. IBM Deep Blue is a heuristic search of all possible moves – like the Logic Theorist from 1955. In 1996, IBM Deep Blue had lost the match, but turned that around a year later by doubling hardware speeds. This along with additional changes to heuristics resulted in Deep Blue’s ability to search 100 million to 200 million positions per second. Like Deep Blue’s 1997 victory, one key ingredient that had evaded neural networks for over five decades since the 1950’s was muscle.
The Final Ingredient for Deep Learning – Fast and Networked GPUs
The recent AI fervor or even fever can be attributed to the success of coupling the power of Graphical Processing Units (GPUs) with neural network. In 2009, Raina et al (Large-scale Deep Unsupervised Learning using Graphic Processors) demonstrated how the use of a GPU could speed up a “four-layer DBN (Deep Belief Network) with 100 million free parameters” up to “70 times faster than a dual-core CPU.” Training that previously took several weeks was reduced to “about a day”. The dramatic increase in performance allowed training of larger networks and larger data sets.
In hind sight, these GPU results do make sense. Consider that regardless of the type of information (e.g. images, video) taken by the neural network as input, it’s always codified into numerical data (e.g. pixels, ratings). Couple that with learning algorithms (essentially complex mathematical computations) being applied on parameters on millions of connections and it does seem like GPUs are a more natural fit. Raina et al explained how GPUs are naturally suited for neural networks when they said GPUs “are able to exploit finer-grained parallelism … designed to maintain thousands of active threads at any time … with very low scheduling overhead.”
The benefit was also observed by several researchers including LeCun and Hinton. In a 2014 interview, he attributed the recent AI explosion by identifying what changed in the 1990’s with this statement “What’s different is that we can run very large and very deep networks on fast GPUs (sometimes with billions of connections, and 12 layers) and train them on large datasets with millions of examples.”
Several others have also attributed the growth of AI to GPUs including NVIDIA’s chief scientist who suggests that “GPUs Ignited AI” and Forbes’ Janakiram who says “In the era of AI, GPUs are the new CPUs”. Even Hinton attributed any limitations on neural networks could addressed by larger GPUs.
So Many Types of Neural Networks
In “A mostly complete chart of Neural Networks” by the Asimov Institute in 2017, they list 34 Neural Networks. Why so many? Well, how the nodes are connected to each other and to themselves will determine what tasks that neural network is best suited for.
Earlier in this article, we spoke of a Convolutional Neural Network (CNN) by LeCun which works best for image recognition. Also known as Deep Convolutional Neural Network (DCNN) when there are multiple hidden layers, they are good for recognizing patterns (e.g. edges, curves, lines) and then pooling them together into progressively high abstractions (e.g. oval, eyes) until the image is identified (e.g. face). For LeCun, it resulted in the ability to read numbers – for others, it was facial recognition.
Then there’s Rosenblatt original neural network from 1958 – the Perceptron, Feedforward NN (FNN) or Deep FNN (DFNN). From the name, you might have already guessed that the connections flow in one direction. While limited in use, it is commonly combined with other networks to form new types.
From Rosenblatt’s Perceptron through the 1980’s (Hopfield Network, Radial Network, Boltzmann machine) to the 90’s (Recurrent networks, long short-term memory) to the 2010’s (Deconvolutional network, Deep convolutional inverse graphics networks), there have been new variants and ultimately combinations of different neural network types to form architectures for specific tasks or problems. As an example, the Deconvolutional network (DN) does the opposite of CNN. Rather than taking an image and identifying the object, DN takes an object name and generates an image of it. Many have used this architecture to generate video, music and scripts.
Considering the ever-increasing types of tasks we’re asking AI to accomplish, we can only expect this list of 34 neural network types to grow. For a deeper explanation of common neural network architectures, read James Le’s article “8 Neural Network Architectures Machine Researchers Need to Learn“.
Neural Network Platforms and Marketplaces
With faster computing power that’s affordable locally and through web services, dozens of neural network platforms including ones with pre-trained models are now widely available. Since the contrast and comparison of these platforms would warrant a whole separate blog, I’ve simply listed a few major platforms with links for more information.
| Vendor and Platform Name | Known For | Pre-trained Models | More Information |
| Amazon SageMaker | Scaleability, reliability and ease of use. General purpose. | Yes. Vision and Language. | aws.amazon.com/sagemaker |
| Google Cloud Machine Learning Engine | Scaleability and performance with custom chips designed to run TensorFlow. | Yes. Vision, Language, Job search, Video Analysis. | cloud.google.com |
| IBM Watson Machine Learning | Fielding Jeopardy winner. Suite of build tools including Visual NN Modeler and Knowledge Catalog for sharing data. | Yes. Language, Vision and Empathy/Tone. | ibm.com/watson |
| Microsoft Azure Machine Learning | Visual Studio Tools and IoT Edge computing | azure.microsoft.com | |
| Salesforce Einstein | Pretrained AI models for CRM | Recommendation, prediction and chatbot. | salesforce.com |
| TensorFlow | Widely used open source software library originally developed by Google. Used for deep learning and runs across multiple platforms. | Yes. Wide variety including Go. | tensorflow.org |
With hundreds of AI engines, there are now several marketplaces for AI developers shopping for AI engines and pre-trained models. Notable ones include Acumos AI and aiWARE. Acumos AI is from the Linux Foundation – known for being open source, sharing of AI models and converting models to microservices. aiWARE from Veritone is a runtime environment for 100+ AI engines and helps you pick the most optimal engine for your model.
AI Gaming Revisited
IBM Watson
Of the platforms listed above, two have made some notable accomplishments. In early 2011, IBM Watson easily beat the two most successful Jeopardy champions in two matches with a total of winning of $112K – the two second place winners only totaled $34K. The competition provided an even playing field as Watson had to voice the question after understanding the spoken answers by Alex Trebek. While being good enough to be on Jeopardy would be an accomplishment for anyone, Watson besting previous champions is a significant victory.
Google’s AlphaGo
In early 2016 and again in 2017, Google’s AlphaGo Lee, based on TensorFlow, beat the Go world champion. Go, a 2,500 year old game, is considered one of the world’s most complex games with more possible moves than chess – that means a larger search space with an exponential explosion that isn’t easily addressed by brute force. If you recall, IBM’s Deep Blue addressed the challenges of chess through more CPUs – i.e. brute force. In 2016, with over 100,000 people watching, Google’s AlphaGo Lee beat 18-time world champion Lee Sedol four games to one. This version of AlphaGo, known as AlphaGo Lee, was trained on a network of over 48 TensorFlow Processors and 30 million human moves and then self-trained by playing different versions of itself. In 2017, Google created AlphaGo Zero which was completely self-trained. Whereas AlphaGo Lee used a dataset of human moves, AlphaGo Zero simply played other versions of AlphaGo. After three days of training, Zero beat AlphaGo Lee in all 100 games. This is an incredible feat for a self-trained AI.
AI 2.0 Is Still Going Strong
The final chapter on AI 1.0 hasn’t been written yet as we continue to see daily breakthroughs in AI with no indication that winter is on its way. Until overly-ambitious expectations or macro-economic events changes that like it did for AI 1.0 or AI 0.5, we will continue to see the growth of AI and its golden child, Neural Networks.
What’s Next For AI?
It’s hard to predict the future of any technology, including AI. Just attend one of the many AI conferences held worldwide and you’ll be certain that AI will affect all aspects of our lives including our consumer experiences. What’s also certain is the break neck speeds at which the breakthroughs are coming – it feels like we’re already living in the future. Here are a few areas that may foretell where AI is headed – Neural Network Chips, AI Edge Computing, AI as a National Interest, Explainable AI and General Intelligence.
Beyond GPUs to Neural Network Chips
Now that neural networks and deep learning have proven the viability of AI, there is now a tremendous amount of work to support faster and larger AI systems. Beyond the platforms and cloud services, one simple approach is to make the hardware faster.
While NVIDIA’s GPUs wasn’t designed for deep learning, they have proven themselves to be more suited to the task then CPUs. What if there was a computer chip designed specifically to run neural networks and to support deep learning? Rather than using logic gates (Nand, Nor), these new chips are modeled after the neuron (or perceptron). As of April 20, 2018, there seems to be more than 19 private and public companies racing to bring a deep learning chip to market.
Leading the charge are traditional chip makers like Nvidia, Intel, and AMD and some companies where AI is strategic to their future – Google, Tesla, Amazon, Uber and Facebook. For the interim, several companies have or are about to add AI features to their smartphone chips – Apple’s AI chip, Qualcomm Snapdragon 700. Additionally, organizations like MIT and ARM are also weighing in with mobile and IoT in mind.
While it’ll be hard to predict the eventual winner or winners here, these chips and possibly their descendants will go a long way to providing the power needed to approach the 86 billion neurons in a human brain.
5G and AI Edge Computing Brings AI to Smartphones and IoT
Isn’t AI already on our smartphones and our smart speakers? The answer is yes for smartphones, but only limited AI is possible through optimizations and other techniques. For smart speakers, the answer is also yes, but only through network connectivity to an AI backend.
Smart Speakers Aren’t So Smart
The reality is that most of our current mobile devices, especially IoT devices, have limited memory or low powered CPUs (without GPUs). As a result, they either can’t host an AI (e.g. smart speakers) or can only host a pruned down version (smartphones).
While smart speakers are always listening, they’re only listening for predetermined keywords (e.g. “OK Google” or “Alexa”). Once activated, there’s a minimal delay where the speaker sends the audio recording to the smart backend where rest of the audio is analyzed. The speech recognition and natural language understanding is really performed in the cloud on more capable servers. Chances are you don’t realize the delay because your home network has low latency, i.e. your broadband and wi-fi is very responsive.
With smartphones, there’s more memory and a faster CPU so some AI can be hosted on the phone. Unfortunately, that’s far from the performance needed to host a full neural network. Fortunately, 5G may be able to help.
5G Enables AI Edge Computing
What if you could experience the same high responsiveness (i.e. lower latency) as broadband but on your mobile network? And what if the GPUs you need on the AI backend are physically located closer to your location so the data will not have to travel across the country (maybe just across the county)? Wouldn’t that allow your dumb IoT device to appear smart or allow your smartphone to appear even smarter? That’s what AI Edge Computing is.
“Observed latency rates” (i.e. responsiveness) in recent 5G trials have ranged from 9-12 milliseconds. When compared with 4G LTE (98 milliseconds) and 3G (212 milliseconds), one can easily see how using 5G can improve responsiveness by a magnitude or more. Now enhance that response time further by reducing the distance your data travel to the AI backends on GPUs at a local Edge Computing center. The final result is full access to AI functionality from your mobile and IoT device that can be almost instantaneous.
Recently, I saw this first hand at the AT&T SPARK conference in San Francisco. At the September 2018 conference, AT&T had a little competition comparing AI with and without Edge Computing. The comparison was made with an AR application that identified movie posters and then played the corresponding movie trailer. The Non-Edge Computing version performed the object identification on the laptop. The Edge Computing version sent the image to GPUs on an Edge Computing cluster. With Edge Computing, the complete time to communicate to the cluster, process the image and return a response was approximately 20 milliseconds. The local, non-Edge Computing version took about two seconds (2000 milliseconds) – a 100X difference. While these tests are early, they are still indicative of the likely gains that AI Edge Computing will provide to smartphones and IoT in the near future.
AI Becomes A National Security Interest … Again

{kind=link}
As we discussed in AI 1.0, during the 1980’s and into 1990’s, the UK, Japan, Europe and the US competed to dominate the next generation of computers. With government coordination and funding, worldwide advances in computer hardware and software technologies, including AI, was undoubtedly accelerated. While primarily focused on commercial applications, some of those advances were coupled with military defense systems such as super computers to reduce radar signatures of stealth jets or to increase image/terrain recognition accuracy for cruise missiles.
Thirty-some years later, with the revival of AI, the competition to dominate commercially and militarily has also awakened. Also there have been significant concerns about the application of AI in Lethal Autonomous Weapons.
Commercial and Military Interests
Commercially, the main commercial players are China and the US – with China leading the way. According to Statista, China outspent the US in 2017 at 48% of all AI startup funding versus US’s 38%. Whomever excels in AI will have a totally epic experience surfing the next wave of innovations such as autonomous vehicles (car, planes, taxis, delivery), predicting consumer behavior, targeting ads, workforce automation, nanotechnology, and IoT. Most others may benefit from some small ankle biters or wipe out altogether.
On the military and defense side, the leaders in the AI Race seem to be China, Russia and the US. On June 15, 2017, Russia’s Vladimir Putin said “the one who becomes the leader in this sphere (AI) will be the ruler of the world.” A month later, China published A Next Generation Artificial Intelligence Development Plan with goals to dominate AI by 2030.
As it turns out, the Obama Administration recognized the military and commercial importance of AI a little earlier when they published Preparing for the Future of Artificial Intelligence in October 2016. In this report, they acknowledged the commercial benefit – “AI holds the potential to be a major driver of economic growth.” They also recognized the military advantages – “(AI) may allow for greater precision in the use of these weapon systems” and “allows an operation to be competed with fewer weapons expended.”
Limitations on Lethal Autonomous Weapons (LAW)
Even without watching the dark Slaughterbot short film that predicts a bleak future with AI assassin drones, it’s not hard to imagine how AI might enhance weapons systems. As it turns out, the military is already working on the next generation of smart weapons. Here are a few reports on current and aspirational projects: swarming airborne drones, naval autonomous ships, unmanned weapons, unmanned fighter jets and robotic soldiers.
While the integration of AI into weapons systems may be inevitable, there’s hope that organizations like the United Nations 2018 Group of Governmental Experts on Lethal Autonomous Weapons Systems (LAWs) will be successful in keeping control of LAWs in human hands. One of the guiding principles as printed in their August 31 2018 report is “Human responsibility for decisions on the use of weapons systems must be retained since accountability cannot be transferred to machines.” Additionally, this sentiment of limiting LAWs is shared by the International Committee of the Red Cross and by over 1,000 AI experts and researchers including Elon Musk, Steve Wozniak, and the late Stephen Hawking.
Explainable AI (XAI)– Trusting AI
When a smart speaker gives you a completely inaccurate or nonsensical answer to a request, it can be quite amusing or even entertaining. Not so much when the decision could be lethal – targeting non-combatants or friendly forces, killing a medical patient or crashing an autonomous car.
For AI systems to be autonomous or to work symbiotically with humans, we must trust them. Before proceeding with any action or after any incident, we must be able to question and understand the AI’s decision. For doctors, that means conferring with the AI system about its diagnosis before proceeding with surgery or certain medication. For soldiers on the battlefield, they must believe the target identification before launching missiles. And for you and me, we must have absolute confidence in our self-driving car’s ability to avoid pedestrians and other cars before we take a nap or watch a movie on our commute home.
And if something were to happen, these same systems must be able to explain their decisions after a lethal misdiagnosis, a friendly fire incident or a car accident. Why did the AI make the decision it did? Why didn’t it make an alternate decision? Not only do we have to understand what went wrong, we also have to correct the AI so it doesn’t happen again. These issues and others are part of a growing field called Explainable AI or XAI.

From “XAI Concept Diagram from Darpa article Explainable Artificial Intelligence (XAI) ” by Mr. David Gunning – DARPA
XAI Wasn’t a Problem for Expert Systems
In AI 1.0, most of the deployed AI systems were Expert Systems. With Expert Systems, explanation wasn’t a problem as the rules that were executed were deliberately coded by knowledge engineers after interviewing domain experts. Due to this approach, when a decision is made, the reason for the decision is fully traceable. In fact, the inference engine can tell you what sequence of rules fired, what those rules are and in many cases, who authored and who audited those rules.
XAI is an Inherent Problem with Neural Networks
If you recall, a trained Neural Networks starts off with random weights on each neuron and its connections. Then the system is trained with data sets where each right or wrong answer will result in the adjustment of all the weights that had a hand in the result. So the final neural network is essentially a collection of these weights that is a result of whatever data set it was trained on.
For any decision or recommendation, an Artificial Neural Network (ANN) can be interrogated to tell you which nodes and connections helped make that decision. This same information is currently used by learning algorithms to adjust the weights during training. Unfortunately, these ANNs cannot tell you why.
Neural networks are great at finding hidden patterns or hidden corollaries in data sets. They’ve been proven to do this better and faster than humans. ANNs like the AlphaGo became a champion Go player in just three days – a feat that would take years for any human. Since ANNs are never taught the principles of a particular domain or field, they don’t know the underlying reasons.
In Siddhartha Mukherjee’s 2017 New Yorker article AI Versus MD, he summarizes an ANN as a self-taught black box who has looked at vast numbers of examples (in this case, pictures of moles versus melanoma). The ANN can easily diagnose a picture as a result of all the training but other than to point to some pictures that your mole resembles, it’ll never know why or give any reason based on medical knowledge. In the same article, Geoffrey Hinton says “A deep-learning system doesn’t have any explanatory power.” Hinton follows up with “the more powerful the deep-learning system becomes, the more opaque it becomes … Why these features were extracted out of millions of other features, however, remains an unanswerable question.”
In the same way that Hinton and others were able to solve the deep learning issues with ANNs, the XAI researchers, like those at IJCAI 2018’s Workshop on XAI will undoubtedly make headway with this problem as well. If not, the deployment of ANNs in critical positions will still happen but more cautiously.
Achieving Artificial General Intelligence
Aspirationally, many think of AI as human-level intelligent – a level where it can assess almost any situation and can respond and adapt. This is known as Artificial General Intelligence (AGI). So far, the majority of deployed AI systems are good at very specific tasks or topics – also known as narrow AI.
From AI 0.5, the Dendral system could produce new chemical structures and from AI 1.0, the American Express Authorization Assistant was successful at recommending denying or authorizing purchases to minimize fraud. For AI 2.0, the narrow AI has gotten much deeper – in Go and Chess, AI has outperformed humans. AI has also gotten wider with smart speakers and IBM Watson displaying an almost omniscient presence on Jeopardy. Now instead of just sticking to a particular task, these AIs can answer general questions and even debate you on any topic. While we’re not at AGI yet and far from HAL 9000 of 2001 Space Odyssey, we’re getting closer. When will we achieve AGI? No one can say for certain but if AI experts like Ray Kurzweil are to be believed, we only about a decade away – Kurzweil predicts AGI by 2029.
How about AI and Entertainment?
Now for something a little lighter … Many of us remember the first time we saw the movie Star Wars (1977) and the realistic, special effects. Between the Millennium Falcon, the Rebel X-Wing fighter and of course, Darth Vader’s TIE Fighter, all the combat scenes looked and felt so real. As it turns out, the use of motion control photography introduced a level of precision that simply wasn’t possible before the introduction of computers.
In the same way, AI’s impact on entertainment could be just as dramatic. As we saw with Symbolics’ Stanley and Stella, AI (or object-oriented technology) created natural schooling behavior in fish and flocking behavior in birds with minimal orchestration. Take a look at some of the recent AI developments in entertainment and you’ll get a hint at where AI and Entertainment will might go.
Story Telling – AI Writes Scripts.
Weaving a good story has always been a creative process limited to humans – until now. In 2016, Ross Goodwin from NYU film school created Benjamin – an AI that can write scripts from seed phrases. Benjamin is a LSTM Recurrent network that wrote scripts by initially predicting the next letters, then words, phrases and ultimately a whole script. After training on existing movie and tv scripts, Goodwin and his colleague, film director Oscar Sharp, generated a script, and based on that script directed a short movie (Sunspring) for a film challenge. While somewhat disjointed, the actor’s interpretation made the short film quite entertaining. If you missed Goodwin and Sharp at AT&T SHAPE 2018, watch them discuss Benjamin’s origin and see a scene acted out live based on a script created by Benjamin.
Storytelling – AI Creates Stories from Images
Similar to Benjamin, Ryan Kiros from University of Toronto created a recurrent neural network to generate stories from images. Kiros’ AI was trained on romance novels and on Taylor Swift lyrics. Like Benjamin’s scripts, the resulting stories are a bit disjointed, but still entertaining.
Storytelling or Storyspoiling – Guesses Perpetrator from CSI Show
Can you guess the outcome of a murder mystery? An AI can. Lea Frermann from University of Edinburgh trained an AI on 39 episodes of CSI: Las Vegas. The result was an AI that was 60% correct in guessing the culprit in the last 10 minutes of the show. Unfortunately, this didn’t beat the human couch potatoes who were 85% correct.
Create Video of Musicians Playing from Musical Audio
Eli Shlizerman and other researchers from Facebook, Stanford University and University of Washington created an AI that takes existing piano and violin music and generates a video of an avatar playing that music. Their LSTM network was “trained on violin and piano recital videos” to learn body poses and hand positions – i.e. body dynamics. Then the predictive AI takes music audio as input, generates animated body, arm and hand poses based on its learnings.
Creating Fake Videos from Spoken Audio
A similar project presented by Suwajanakorn et al at SIGGRAPH 2017 shows the generation of talking heads video based on spoken audio. Taking 14 hours of speeches from President Obama, Suwajanakorn trained his AI on Obama’s mouth movement relative to what was said. Then his AI could synthesize lip sync’d video based on audio of other speeches Obama made. If you look at the videos carefully, you’ll be surprised as to how realistic the fake videos are.
Human Sounding AI
Now that AI can write scripts from ideas or images, create musicians from audio and create character mouth motions to deliver dialog, what about creating believable human speech? Fortunately, Google has this last bit covered with Duplex. Whereas current computer-generated voices do not sound natural, Duplex sounds indistinguishable from humans – even throws in filler words like “um” and “ah”. Albeit they’re only using it to assist you with restaurant reservations, there’s no reason why this same technology couldn’t be used to create natural speech for AI created characters and dialog in an AI generated script.
Augmented Reality Interacting with Your Environment
It’s one thing to see characters and objects in your AR environment such as a Pokémon character walking in front of you. What if those characters interacted with your environment? What if they hid behind objects or better yet, recognized an empty couch and sat down to have a discussion with you? Wouldn’t their behavior look more realistic and most importantly believable? In 2018, Niantic will make their Real World Platform available to AR developers. Their platform uses neural networks to understand objects are in the environment and the types of interactions your characters can have with them.
Will AI Create a Whole Movie?
Conceivably, this can be done. Given what we’ve seen, AI can already create the script, voice the actors, generate the lip movement, write the soundtrack and generate the extras. Can AI generate subtle body movements by the leading actors to convey the desired emotion? Not today but if it can create musicians from music then why not movements from emotion? Most of the pieces are already there.
The first few attempts at movie creation will undoubtedly be more amusing then entertaining but like any good Deep Learning Neural Network, this AI will just train itself based on audience feedback and evolve until it gets it right. These are exciting times.
Final Words
The evolution of AI has been a long journey and over the course of 60 plus years, we’ve seen significant foundational work and many surprising twists and turns.
From Marvin Minsky’s 1951 grand piano-sized 40 node neural network to GPU chips to the recent Neuromorphic super computer approaching one billion neurons, the hardware advancements has been astonishing. Equally impressive has been the advancements in software and software tooling – e.g. lists to LISP to object-oriented languages. For more than 60 years, each software and hardware development has laid the foundation for subsequent discoveries. Today’s neural networks would not be possible without inexpensive memory chips or the speed of GPUs or the massive amounts of data from the internet and our mobile devices. Essentially AI has grown as fast as computer hardware and software has allowed it to.
While hardware speeds have been predictable (Moore’s law), determining which AI technologies would bear fruit has not. Through AI 0.5, AI 1.0 and AI 2.0, we’ve seen promising technologies such as neural networks blossom, go dormant and then surprisingly, revive back to life again proliferating many aspects of our life.
At the end of AI 0.5, Marvin Minsky’s 1969 Perceptrons: An Introduction to Computational Geometry which critiqued the inadequacy of learning algorithms, all but killed neural network research. During AI 1.0, AI researchers and enterprise developers focused primarily on Expert Systems and Lisp-based systems. Meanwhile, without reward and fanfare, Geoffrey Hinton and other researchers were quietly making breakthroughs in Deep Learning and Machine Learning. Now some 30 years later, because of their work, AI has touched everyone’s lives with applications such as AI assistants, turn-by-turn directions and internet searches. AI owes this latest revival to ML and DL researchers like Hinton.
Just as most AI industry experts during AI 1.0 could not have predicted today’s dominance by neural networks, we should also expect to be equally surprised at what blossoms in next 10 to 20 years.