AT&T Video Optimizer
Periodic Transfers
Introduction
Periodic transfers are specific packets that are sent repeatedly by a server over an infinite time horizon. They typically occur at regular intervals, and the timing of the intervals can be adjusted.
Two common uses of periodic transfers are:
- Requests for analytics information
- Keepalive pings
Periodic transfers can be very useful, but it is easy to mismanage them to the point where they can waste energy and slow down an application.
This Best Practice Deep Dive gives some background on what the most commonly used periodic transfers are and what they are typically used for. It explains the issue of how periodic transfers can cause an application to drain energy and offers recommendations on how to use periodic transfers effectively so that they have the least effect on user experience and network resources.
Background
By understanding the two most common uses of periodic transfers—analytics and keepalive pings—we can see why they are useful to an application.
Analytics
Analytics information is gathered for measurement, collection, analysis and reporting of data to help businesses better understand their application and how it is being used by customers. The information typically consists of data like the number of page views, traffic trends, and the effects of advertising and other market research.
The following types of analytics methods are commonly used in mobile applications:
- Image tags or beacons
- Link redirection
- HTTP header analysis
- IP address analysis
- WAP Gateway Traffic logs
When choosing an analytics method, it's important to keep down additional overhead. For instance, it's a good idea to avoid using large files for image tagging, if their only purpose is analytics.
Keepalives
Using the same TCP connection over the life of an application allows the server and the application to communicate in real time. In order to maintain a connection, applications use keepalives to ensure the connection isn't closed due to a timeout.
Keepalives are a type of ping. In an IP network, a ping is any short data burst which listens for a reply. So a keepalive ping is a message sent by one device to another to check that the connection between the two is still open, or to prevent the connection from being ended.
When you establish a TCP connection, you associate a set of timers with the connection. These timers can be used to keep the connection up and running, or alive.
When the keepalive timer reaches zero, a keepalive segment is sent with no data in it and the ACK flag turned on, as a sort of duplicate ACK. The other side will have no arguments, as TCP is a stream—oriented protocol. The initiating party will receive a reply from the other side, with no data and the ACK set.
Once a reply is received by a keepalive probe, it is understood that the connection is still up and running.
TCP RFC: 793—https://www.ietf.org/rfc/rfc793.txt
The Issue
Resource allocation and the energy state for a device are the result of a negotiation between the network and an application. When a device needs to transmit data, it signals the network and the network allocates a dedicated channel; or if data is being transmitted to the device, the network alerts the device. The culmination of this process is a promotion of the device to full power so that it can transmit data.
The network conserves capacity by opening connections only when needed, but the overhead in opening a connection — the exchange of control messages between network and device, and the calculations needed to determine whether sufficient capacity is available—introduces a delay, or latency, of between one and two seconds. This means that even the necessary process of resource allocation is a source of latency on the wireless network.
Sending even one extra packet that could have been reduced means the wireless radio was turned on needlessly and this overhead was incurred. When an application requires periodic transfers, each transfer potentially incurs a long tail when closing the radio transmission, and that wastes energy and increases network congestion.
Over time, pinging the network repeatedly for analytics or advertising, for example, uses more power than delivering the actual content your users want. By reducing the number of these pings, you can greatly reduce the battery drain of your application.
The following table (figure 1) contains an analysis of trace results that show the effect of periodic transfers on the energy usage of an application.
These trace results were captured using the AT&T Video Optimizer diagnostic tool. The Video Optimizer tool collects trace data from an application, evaluates it against recommended best practices, and generates analytical results. Figure 1 shows the Burst Analysis table from the Statistics tab of the Video Optimizer tool.
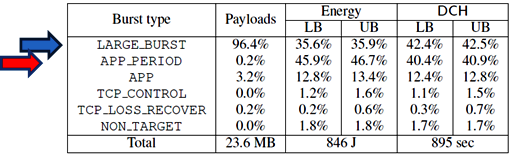
Figure 1: Burst Analysis statistics (J=Joules LB= Lower Bound results UB= Upper Bound results)
In the application analyzed in figures 1 and 2, user data is transmitted in large bursts, and analytics are transmitted every minute in periodic bursts. The blue arrow represents the actual content and the red arrow represents periodic transfers. Even though periodic transfers only account for 0.2% of the payload, they account for more than 40% of the energy usage and time delays. It's a small issue with a big impact.
Figure 2 is taken from the Trace chart in the Diagnostics tab of the Video Optimizer tool, and it highlights the issue in context. Over time, pinging the network repeatedly for analytics or for advertising (red arrows) uses more power than delivering the actual content (blue arrow) your users want. By reducing the number of these pings, you can greatly reduce the battery drain of your application.
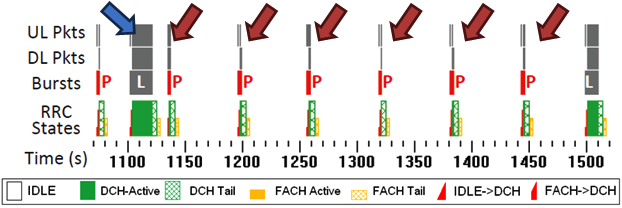
Figure 2: Trace results showing periodic pings
As discussed above, another common reason for periodic pings is to keep a TCP connection alive.
Using the same TCP connection over the life of the application allows the server and the app to communicate in real time. And here's something you might not know. As we will see below, there may be less need than you think to use periodic pings to ensure the connection isn't closed due to timeout.
Best Practice Recommendation
The Best Practice Recommendations for using periodic transfers effectively in a wireless application are:
- Determine the best timing for analytics and keepalives so that your application uses as long a period as possible between transfers.
- Use piggybacking to combine analytics with other data and remove standalone pings.
- Use batching to bundle as much data as possible into a single message.
Experiment with different scenarios to determine which combination of periodic transfer timing, piggybacking and batching can improve your application the most
Determining the Best Timing
To determine the most efficient time period between transfers for analytics and keepalives, begin by asking these questions about your application.
Analytics:
- Do updates really need to be sent every few seconds?
- How much delay between updates can the application tolerate?
- Is it possible to use bigger updates that are sent less frequently?
- Could the timing of the updates be more adaptive? For example, could a longer period be used under normal conditions, and a shorter period be used if needed?
Keepalives:
- Do keepalives really need to be sent so frequently?
- Default TCP Keepalive times are quite long. Does my application need more?
- Is it important to the application to keep firewall connections alive?
- Given the firewall timeout values to keep my TCP connection alive, can I send keepalives at a shorter interval than the firewall timeout?
When answering these questions, it's important to understand the timing of TCP timeouts on wireless networks. Consider that AT&T's firewall keepalive is 30 minutes, and the shortest TCP timeout that we have found among major carriers is 4 minutes. This indicates that sending a ping every minute or so just to keep the connection alive is not necessary. A period of several minutes rather than one of a few seconds would be more appropriate for most applications.
Piggybacking
TCP piggybacking is the process of sending data along with an acknowledgement. Piggybacking lets both sides of the TCP conversation send data at the same time.
This technique reduces the overhead of the transmissions by carrying bidirectional traffic. The data packets transmitted in one direction contain the acknowledgements for the data transmitted in the other direction. When the receiving node has to acknowledge some received packets, it can wait for the next data packet to be sent and put the acknowledgement information in the header, so that it doesn't have to send a separate TCP ACK packet.
Piggybacking can be used to eliminate standalone pings by combining analytics with the other data that is being transmitted by your application.
Batching
Batching or bundling data refers to using a single TCP segment to send all the data from a specified sequence numberup to the maximum permitted by the segment window. When used appropriately, sending multiple messages down the networking stack in one batch can reduce latency.
By analyzing the periodic transfers in your application and identifying tasks that can be grouped together, you can make use of batching to improve speed and reduce energy usage.
Experimenting with Different Scenarios
In order to find the optimal timing for your periodic transfers and determine whether piggybacking and batching can improve your application, you can experiment with different scenarios. In our research, we did just that.
The following chart (figure 3) shows energy usage and radio state time for the original traffic pattern compared against three other "what-if" traffic pattern scenarios:
- Removing Ads: The Original traffic pattern with all of the Ads removed.
- Piggyback: As many of the Ads as possible are piggybacked with non-ad traffic.
- Batching: The Ads are batched together with the non-ad traffic.
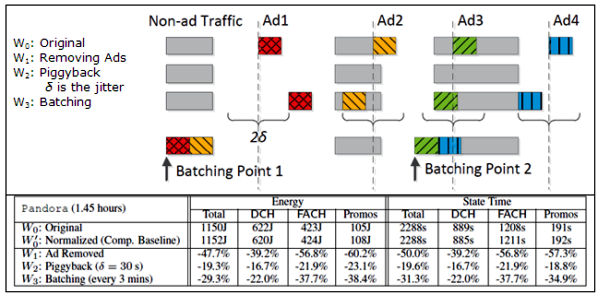
Figure 3: Comparison of energy usage and radio state time for three traffic patterns.
As you can see from this comparison, managing periodic transfers by sending them less frequently, or by using techniques like piggybacking and batching, can save energy and reduce radio state time.